

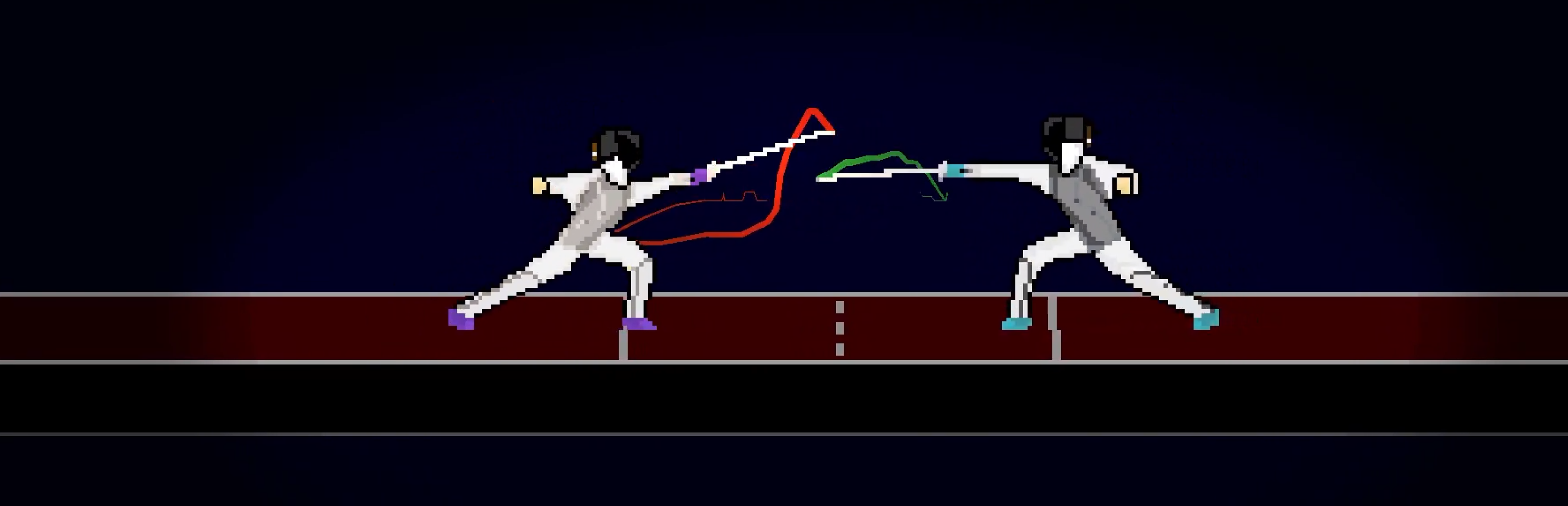
Body Trails - A Visual Aesthetic
Colored visual effect that trails delayed


Without searching up guides or answers, I programmed my own AI from scratch.
My AI controls the opponent when the user chooses to play offline. However, the difficulty is in designing an opponent that plays like a human–you know, unpredictable and random. So, my AI uses “Probalistic Modeling”: instead of a simple “yes/no” decision, these models utilize a percentage chance of an event occurring (e.g. a 5% chance to jump). Therefore, every action of the opponent AI is determined by set chances. For example, the AI may randomly parry based on a low percentage, or rather when hit, there is a chance to parry the attack. This model keeps the decisions of the AI fresh and varied. Instead of fighting the same opponent continuously, you experience a new game each time you press play.

However, the opponent can not be entirely random. I lied when I joked that humans are random–in reality, human fencers have strengths which they are aware of, and even worse, they are aware of YOUR weaknesses. They will do anything to abuse your downfalls and score a point. Similarly, human players of fighting games have their own playstyles, which they represent through their actions and chosen characters. All in all, humans are not random, but intentional. They press “Play” already knowing their gameplan, then adapt it over the course of the match. My AI needs to reflect this. It needs to be customizable towards specific archetypes. Furthermore, during bouts, it needs to adapt in real-time, shifting its predetermined archetype. Thus, my AI has several settings that range from 0.0 to 1.0. These settings manipulate the aforementioned chances.
Later, I’ll go more in depth on the individual settings. For now, the settings are named as follows:
#All are from 0 to 1
#EDIT PER CHARACTER
@export var keepsDistance : float
#EDIT THESE PER DIFFICULTY
@export var reactionSetting : float
@export var spamSetting : float
@export var agroSetting : float
@export var parrySetting : float
@export var carefulSetting : float
@export var awakeSetting : float
@export var punishSetting : float
@export var blockSetting : float
@export var beatSetting : float
Remember my example of “… or rather when hit, there is a chance to parry the attack.”? Well, this can’t be set-in-stone, now can it? Imagine you’re fighting an AI with a rushdown archetype (so, close-up and aggressive, e.g. high spamSetting and agroSetting but low carefulSetting). Let’s say the AI keeps running up and spamming attacks. If you keep utilizing right of way to score double-touches (so, no matter what the AI attacks you with, you still get the point), shouldn’t the AI change its gameplan? A real human would! Therefore, my AI adapts its probability model over time to the actions of the player. If you keep hitting the rushdown AI, it will note that you attack often, therefore it will increase its chance to parry. That aforementioned “chance to parry the attack” will go up because the AI will expect you to attack more often.
The AI stores your actions as follows:
var weightsTypes = {
"Attack": 0.0,
"Defense":0.0,
"Movement":0.0,
"Beat":0.0,
"Throw":0.0,
"Utility":0.0,
"Super":0.0,
"Taunt":0.0
}
#... skip a lot of lines ...
func enemyActionDone(player : CharacterBody2D, actionName : String, actionType : String, actionCategory : String, range : Vector2,duration : float): #note that "enemy" refers to the enemy of the AI, thus the player in our example
if player != chara: #chara is the AI's CharacterBody2D
if actionType == "Attack":
if actionCategory =="Light":
weightsTypes[actionType] = clampf(weightsTypes[actionType] + 1.0,0.0,40.0)
else:
weightsTypes[actionType] = clampf(weightsTypes[actionType] + 2.5,0.0,40.0)
else:
weightsTypes[actionType] = clampf(weightsTypes[actionType] + 1.0,0.0,40.0)
#maximumRange = range
beginReaction(actionCategory == "Heavy")
#... skip lines ...
func _physics_process(delta : float) -> void:
for i in range(weightsTypes.size()):
weightsTypes[weightsTypes.keys()[i]] = snapped(clampf(weightsTypes[weightsTypes.keys()[i]] - 0.003,0.0,80.0),.001) #slowly forget about the enemy's decisions
As you can see, many action types are stored by the AI. When you commit to specific actions, the AI notes accordingly (and if you attack with a more committal, larger attack, the AI adds more weight to it). But, over time, these values are decreased. After all, if you the player change your gameplan, the AI should not be stuck in its old ways. This is especially important so that the player can not simply act one way to fool the AI, then completely switch up to get easy points. For example, to speedrun the Arcade mode, the player may spam attacks at the start of every round, and when the AI begins to spam parries in response, the player constantly runs up and grabs to push the AI off the strip. I don’t want any of that!
Remember, you lose right of way if you miss an attack. The AI should know this. The probilistic model shifts depending on whether the opponent AI has right of way. For example, as seen below, if RoW is possessed, the AI will get closer and be less likely to do a raw attack. Of course, losing right of way is also its own chance–the AI may suddenly walk backward and lose RoW all because it got unlucky. Note: this “chanceToLoseRoW” is what enables most other possible actions; this chance must occur before the AI can run the chance of giving up right of way (walking backward, randomly attacking, etc.) This chance starts at 1.0 (100% likely to occur), meaning that the AI can do whatever it wants without fear of losing RoW. However, if RoW is possessed, this number decreases drastically. If you’re still confused, here’s an easy explanation:
Here’s the code as promised:
func setVariables():
#...
chanceToLoseRoW = 1.0
if roW == chara:
minComfortDistance-=15.0
maxComfortDistance-=20.0
chanceToParryNew -= .26
chanceToChangeMovement -= 0.2
newChanceToSkipAction -= .1 #the chance is 1.0 - this... oops, too late, whatever
chanceRawAttack -= .2
chanceRawBigAttack += .12
chanceToLoseRoW = snapped(0.4-(carefulSetting/6.0)+(spamSetting/5.0)-(awakeSetting/5.0),.001)
chanceToBlock -= .2
chanceToBeat += .15
elif roW != chara and roW != null:
minComfortDistance+=12.0
maxComfortDistance+=17.0
chanceToParryNew += .25
chanceToChangeMovement += 0.2
chanceRawAttack += .2
chanceRawBigAttack -= .07
chanceToParryReact -= .1
chanceToBlock += .2
chanceToBind += .1
WIP
Unfortunantely, all these numbers seen thus far have to be manually set. That takes A LOT of trial and error. WIP
The AI will change so much over time, especially as I continue my trial-and-error.
Ideally, I want to implement a “Bayesian Interface”, which is a statistics method of updating probability based on new information.
Note: this will change a lot, but will not be updated often; I change specific chance numbers almost every day. This is the May 5th code:
extends Node
var roW : CharacterBody2D = null
var moveList
var attackList : Array[String]
var blockAll = false
#All are from 0 to 1
#EDIT PER CHARACTER
@export var keepsDistance : float
#EDIT THESE PER DIFFICULTY
@export var reactionSetting : float
@export var spamSetting : float
@export var agroSetting : float
@export var parrySetting : float
@export var carefulSetting : float
@export var awakeSetting : float
@export var punishSetting : float
@export var blockSetting : float
@export var beatSetting : float
var globalSettings = null
var prevCurrentAction : String
var currentAction := ""
var previousAction = ["Action","Type"]
var weightsTypes = {
"Attack": 0.0,
"Defense":0.0,
"Movement":0.0,
"Beat":0.0,
"Throw":0.0,
"Utility":0.0,
"Super":0.0,
"Taunt":0.0
}
@onready var chara = get_parent()
var enemy : CharacterBody2D
var enemySM : Node
var rng = RandomNumberGenerator.new()
var connected = false
var enemyActionName
var enemyActionType
var enemyActionRange
var enemyActionDuration
var comfortable := false
var additionalRange : float = 0.0
var minComfortDistance #max distance away the AI wants to be
var maxComfortDistance #max closeness the AI wants to be
var chanceToChangeMovement
var chanceToIdle
var chanceToLoseRoW := 1.0 #chance to idle or walk backwards
var reactionTime
var punishTime
var chanceToSkipAction #really, the "chance" would be (1.0 - this)
var newChanceToSkipAction
var chanceToRawAttack
var chanceToAllowRawBigAttack
var chanceRawAttack
var chanceRawBigAttack
var chanceToParry
var chanceToParryNew
var chanceToParryReact
var chanceToPunish
var chanceToBlock
var chanceToBeat
var chanceToBind
var additionalRangeForSpam
var variablesSet := false
"""
@onready var minComfortDistance = 65.0 + int(keepsDistance*20) - int(agroSetting*10) #max distance away the AI wants to be
@onready var maxComfortDistance = 35.0 + int(keepsDistance*20) - int(agroSetting*10) #max closeness the AI wants to be
var chanceToChangeMovement = snapped(.23+(carefulSetting/5.0),.001)
var chanceToIdle = snapped(.18-(agroSetting/6.0),.001)
var comfortable := false
@onready var reactionTime = (23-(round(6.5*reactionSetting))) * (0.0167)
@onready var chanceToSkipAction = snapped(.7-(carefulSetting/5.0),.001) #really, the "chance" would be (1.0 - this)
var newChanceToSkipAction = chanceToSkipAction
@onready var chanceToRawAttack = clampf(snapped(.05+(agroSetting/7.0)+(spamSetting/2.0)-(carefulSetting/6.0),.001),0.05,0.7)
@onready var chanceToAllowRawBigAttack = clampf(snapped(.1+(agroSetting/6.0)-(spamSetting/5.0)-(carefulSetting/3.0),.001),.05,.15)
var chanceRawAttack = chanceToRawAttack
var chanceRawBigAttack = chanceToAllowRawBigAttack
@onready var chanceToParry = snapped(.5+(parrySetting/3.0)+(carefulSetting/8.0)-(agroSetting/6.0),.001)
var chanceToParryNew = chanceToParry
var additionalRange : float = 0.0
@onready var additionalRangeForSpam = snapped(15.0+(chanceToAllowRawBigAttack*40),.001)
"""
var maximumRange : Vector2
var reacting := false
var responding := false #once reacting timer expires, the AI is now "responding"
var punishing := false
var queuing := false
var queuedType
var queuedCategory
var queuedMustBeCategory
var distance : float
@onready var stateMachine = chara.get_node("StateMachine")
@onready var currentState = stateMachine.currentState
@onready var label = chara.get_node("AILabel")
@onready var label1 = chara.get_node("AILabel1")
@onready var labelWeights = chara.get_node("AILabelWeights")
@onready var AILabelThinking = chara.get_node("AILabelThinking")
@onready var SliderReaction = chara.get_node("SliderReaction")
@onready var SliderSpam = chara.get_node("SliderSpam")
@onready var SliderAgro = chara.get_node("SliderAgro")
@onready var SliderParry = chara.get_node("SliderParry")
@onready var SliderCareful = chara.get_node("SliderCareful")
func setLists():
var moveListStorage = chara.get_node("MoveListStorage")
moveList = moveListStorage.getListFromCharacter[chara.character][0]
#if chara.character == "Sho":
# moveList = moveListStorage.shoMoveList
# attackList = moveListStorage.shoAttackList
func updateOriginalVariables():
reactionSetting = SliderReaction.value
spamSetting = SliderSpam.value
agroSetting = SliderAgro.value
parrySetting = SliderParry.value
carefulSetting = SliderCareful.value
func setVariables():
if not variablesSet:
if globalSettings != null: #spamSetting,agroSetting,parrySetting,carefulSetting
reactionSetting=globalSettings[0]
spamSetting=globalSettings[1]
agroSetting=globalSettings[2]
parrySetting=globalSettings[3]
carefulSetting=globalSettings[4]
awakeSetting=globalSettings[5]
punishSetting=globalSettings[6]
blockSetting=globalSettings[7]
beatSetting=globalSettings[8]
else: #TODO this is where the base se
reactionSetting=get_node("/root/Selections").aiTypes[0][0]
spamSetting=get_node("/root/Selections").aiTypes[0][1]
agroSetting=get_node("/root/Selections").aiTypes[0][2]
parrySetting=get_node("/root/Selections").aiTypes[0][3]
carefulSetting=get_node("/root/Selections").aiTypes[0][4]
awakeSetting=get_node("/root/Selections").aiTypes[0][5]
punishSetting=get_node("/root/Selections").aiTypes[0][6]
blockSetting =get_node("/root/Selections").aiTypes[0][7]
beatSetting =get_node("/root/Selections").aiTypes[0][8]
var weightAdd = weightsTypes["Attack"]/7.0-weightsTypes["Defense"]/3.5
minComfortDistance = 85.0 + int(keepsDistance*17) - int(agroSetting*13) + weightAdd #max distance away the AI wants to be
maxComfortDistance = 60.0 + int(keepsDistance*17) - int(agroSetting*13) + weightAdd #max closeness the AI wants to be
chanceToChangeMovement = snapped(.05-(carefulSetting/15.0)+(spamSetting/10.0)+(agroSetting/6.0),.001)
chanceToIdle = snapped(.21-(agroSetting/6.0),.001)
var reactionTimeFrames = 24 - round(7*reactionSetting) - round(6*awakeSetting) + randi_range(-1,3)
reactionTime = (reactionTimeFrames - round(weightsTypes["Attack"]/15.0)) * (0.0167)
punishTime = ((reactionTimeFrames) - (round(5*punishSetting))) * (0.0167)
chanceToPunish = snapped(.39+(punishSetting/2.5)+(awakeSetting/3.5)+(carefulSetting/8.0)-(spamSetting/5.0)-(agroSetting/7.0) - (distance/700.0),.001)
chanceToSkipAction = snapped(.5+(carefulSetting/11.0)+(punishSetting/7.0)-(spamSetting/5.0),.001) #really, the "chance" would be (1.0 - this)
newChanceToSkipAction = chanceToSkipAction
chanceToRawAttack = .27+(agroSetting/6.0)+(spamSetting/1.5)-(carefulSetting/6.5)-(blockSetting/10.0)-(awakeSetting/9.0)+(beatSetting/10.0)-(parrySetting/9.0)
chanceToAllowRawBigAttack = .1+(agroSetting/4.0)-(spamSetting/5.0)-(carefulSetting/4.0)+(awakeSetting/9.0)-(punishSetting/8.0)
chanceRawAttack = chanceToRawAttack
chanceRawBigAttack = chanceToAllowRawBigAttack
chanceToParry = snapped(.12+(parrySetting/2.25)+(carefulSetting/10.0)-(agroSetting/6.0)-(spamSetting/7.0)+(awakeSetting/6.0)+(punishSetting/9.0),.001)
chanceToParryNew = chanceToParry
chanceToParryReact = snapped(chanceToParry + (awakeSetting/2.0)+(punishSetting/5.0) - (spamSetting / 7.0) - (agroSetting/8.0),.001)
chanceToBlock = snapped(.13+(blockSetting/2.0)+(carefulSetting/9.0)-(agroSetting/3.5)-(spamSetting / 3.5)+(awakeSetting/3.0),.001)
chanceToBeat = snapped(.24+(beatSetting/3.0)-(carefulSetting/11.0)+(agroSetting/6.0)+(spamSetting / 7.0)+(punishSetting/8.0),.001)
chanceToBind = snapped(.14+(carefulSetting/11.0)-(spamSetting / 10.0)+(punishSetting/3.5)+(awakeSetting/7.0)+(agroSetting/9.0),.001)
additionalRangeForSpam = snapped(15.0+(chanceToAllowRawBigAttack*40),.001)
chanceToLoseRoW = 1.0
if roW == chara:
minComfortDistance-=15.0
maxComfortDistance-=20.0
chanceToParryNew -= .26
chanceToChangeMovement -= 0.2
newChanceToSkipAction -= .1 #the chance is 1.0 - this
chanceRawAttack -= .2
chanceRawBigAttack += .12
chanceToLoseRoW = snapped(0.4-(carefulSetting/6.0)+(spamSetting/5.0)-(awakeSetting/5.0),.001)
chanceToBlock -= .2
chanceToBeat += .15
elif roW != chara and roW != null:
minComfortDistance+=12.0
maxComfortDistance+=17.0
chanceToParryNew += .25
chanceToChangeMovement += 0.2
chanceRawAttack += .2
chanceRawBigAttack -= .07
chanceToParryReact -= .1
chanceToBlock += .2
chanceToBind += .1
variablesSet = true
func updateChanceVariables():
chanceToParryNew=clampf(snapped(chanceToParryNew+weightsTypes["Attack"]/140.0-weightsTypes["Defense"]/60.0-(distance/260.0),.01),.058,0.75)
chanceToParryReact=clampf(snapped(chanceToParryReact+weightsTypes["Attack"]/110.0-weightsTypes["Defense"]/80.0-(distance/200.0),.01),.058,0.75)
chanceRawAttack = clampf(snapped(chanceRawAttack-(distance/1300.0),.001),0.05,0.92)
chanceRawBigAttack = clampf(snapped(chanceRawBigAttack+(distance/900.0),.001),.04,.6)
chanceToChangeMovement = clampf(snapped(chanceToChangeMovement-(distance/1300.0),.001),0.03,0.25)
#chanceToBeat=clampf(snapped(chanceToBeat+weightsTypes["Attack"]/110.0-weightsTypes["Defense"]/80.0-(distance/200.0),.01),.058,0.75)
chanceToBlock=clampf(snapped(chanceToBlock+weightsTypes["Attack"]/120.0-weightsTypes["Defense"]/90.0-(weightsTypes["Beat"]/90.0),.01),.2,0.77)
chanceToBind=clampf(snapped(chanceToBind+(weightsTypes["Beat"]/55.0),.01),.05,0.6)
func _ready() -> void:
#print("waiting...")
await chara.get_node("LastToLoad").ready
if not get_parent().aiMode:
label.queue_free()
label1.queue_free()
labelWeights.queue_free()
SliderReaction.queue_free()
SliderSpam.queue_free()
SliderAgro.queue_free()
SliderParry.queue_free()
SliderCareful.queue_free()
get_parent().get_node("FreezeAIButton").queue_free()
chara.get_node("SliderInfo").queue_free()
queue_free()
setVariables()
setLists()
SliderReaction.value = reactionSetting
SliderSpam.value=spamSetting
SliderAgro.value=agroSetting
SliderParry.value=parrySetting
SliderCareful.value=carefulSetting
func _process(delta: float) -> void:
#updateOriginalVariables()
setVariables()
updateChanceVariables()
setLabelText()
func _physics_process(delta: float) -> void:
if not variablesSet:
return
if enemy != null and not connected:
connected = true
enemy.actionDone.connect(enemyActionDone)
enemy.hitboxGone.connect(enemyHitboxGone)
currentState = stateMachine.currentState
distance = snapped(chara.position.distance_to(enemy.position),.001)
if distance > minComfortDistance or distance < maxComfortDistance:
comfortable = false
else:
comfortable = true
"""
if rng.randf_range(0,1) < chanceToChangeMovement:
if distance > minComfortDistance or rng.randf_range(0,1) < chanceToChangeMovement / 5.0:
doConstantAction("WalkForward",Vector2(1,0))
comfortable = false
elif distance < maxComfortDistance or rng.randf_range(0,1) < chanceToChangeMovement / 12.0:
doConstantAction("WalkBackward",Vector2(-1,0))
comfortable = false
elif rng.randf_range(0,1) < chanceToIdle: #dont wanna lose right of way yk
doConstantAction("Idle",Vector2(0,0))
comfortable = true
"""
for i in range(weightsTypes.size()):
weightsTypes[weightsTypes.keys()[i]] = snapped(clampf(weightsTypes[weightsTypes.keys()[i]] - 0.003,0.0,80.0),.001)
#if responding:
# return
if queuing and currentState == currentState.neutralState: #TODO what about reacting?
chooseAction(queuedType,queuedCategory,0,queuedMustBeCategory)
#if queuing:
# return
#if punishing:
# return
if responding or queuing or punishing:
return
if comfortable:
processComfortable()
elif distance < maxComfortDistance:
processTooClose()
elif distance > minComfortDistance:
processTooFar()
"""
if rng.randf() < chanceToChangeMovement/5.0:
if comfortable:
if rng.randf() < .2:
chooseAction("Movement","Dash",0,false)
elif rng.randf() < .3:
chooseAction("Movement","Backdash",0,false)
elif distance<maxComfortDistance and rng.randf() < .5:
chooseAction("Movement","Backdash",0,false)
elif distance>minComfortDistance and rng.randf() < .2:
chooseAction("Movement","Dash",0,false)
elif (rng.randf_range(0,1) < chanceRawAttack/5.0) or (comfortable and rng.randf_range(0,1) < chanceRawAttack): #spam raw attack when at a comfortable distance
if rng.randf_range(0,1)<chanceToParryNew:
chooseAction("Defense","Parry",0,true)
elif rng.randf_range(0,1) < chanceRawBigAttack:
#print("AI is allowing a raw big attack!") #allowing; wont always be big, just allows the possibility
chooseAction("Attack","Medium",0,false)
else:
additionalRange = additionalRangeForSpam
chooseAction("Attack","Light",0,true)
"""
func processComfortable():
if rng.randf() < chanceToChangeMovement:
if roW == enemy and rng.randf() < .2:
doConstantAction("WalkForward",Vector2(1,0))
elif roW != enemy and rng.randf() < .4:
doConstantAction("WalkForward",Vector2(1,0))
elif rng.randf() < chanceToLoseRoW and rng.randf() < .19: #the "and" is important here. the first will only be false if in possession of RoW (see setVariables()).
doConstantAction("Idle",Vector2(0,0))
elif (roW == enemy and rng.randf() < .8) or (roW == self and rng.randf() < chanceToLoseRoW): #the "and" is important here. the first will only be false if in possession of RoW (see setVariables()).
doConstantAction("WalkBackward",Vector2(-1,0))
return
if rng.randf() < chanceToChangeMovement/32.0:
if rng.randf() < .35:
chooseAction("Movement","Dash",0,false)
elif rng.randf() < chanceToLoseRoW:
chooseAction("Movement","Backdash",0,true)
elif rng.randf_range(0,1) < chanceRawAttack: #spam raw attack when at a comfortable distance
if rng.randf_range(0,1)<chanceToBind:
chooseAction("Beat","Bind",0,true)
elif rng.randf_range(0,1)<chanceToBeat:
chooseAction("Beat","Beat",0,true)
elif rng.randf_range(0,1)<chanceToParryNew:
chooseAction("Defense","Parry",0,true)
elif rng.randf_range(0,1) < chanceRawBigAttack:
#print("AI is allowing a raw big attack!") #allowing; wont always be big, just allows the possibility
chooseAction("Attack","Medium",0,false)
else:
additionalRange = additionalRangeForSpam
chooseAction("Attack","Light",0,true)
func processTooClose():
if rng.randf() < chanceToChangeMovement / 1.25:
if rng.randf() < .05:
if rng.randf() < .08:
chooseAction("Movement","Dash",0,false)
else:
doConstantAction("WalkForward",Vector2(1,0))
elif rng.randf() < .12:
doConstantAction("Idle",Vector2(0,0))
elif rng.randf() < chanceToLoseRoW:
if rng.randf() < .35:
chooseAction("Movement","Backdash",0,true)
return
else:
doConstantAction("WalkBackward",Vector2(-1,0))
"""
if rng.randf() < chanceToChangeMovement/5.0:
if rng.randf() < .05:
chooseAction("Movement","Dash",0,false)
return
elif rng.randf() < .4:
chooseAction("Movement","Backdash",0,false)
return
"""
if (rng.randf_range(0,1) < chanceRawAttack):
if rng.randf_range(0,1)<chanceToBind:
chooseAction("Beat","Bind",0,true)
elif rng.randf_range(0,1)<chanceToBeat/1.3:
chooseAction("Beat","Beat",0,true)
elif rng.randf_range(0,1)<chanceToParryNew * 1.8:
chooseAction("Defense","Parry",0,true)
elif rng.randf_range(0,1) < chanceRawBigAttack / 4.0:
#print("AI is allowing a raw big attack!") #allowing; wont always be big, just allows the possibility
chooseAction("Attack","Medium",0,false)
else:
additionalRange = additionalRangeForSpam
chooseAction("Attack","Light",0,true)
func processTooFar():
if rng.randf() < chanceToChangeMovement * 1.25:
if rng.randf() < .03:
if rng.randf() < .2:
chooseAction("Movement","Backdash",0,true)
else:
doConstantAction("WalkBackward",Vector2(-1,0))
elif rng.randf() < .12:
doConstantAction("Idle",Vector2(0,0))
else:
if rng.randf() < .32:
chooseAction("Movement","Dash",0,true)
else:
doConstantAction("WalkForward",Vector2(1,0))
return
if (rng.randf_range(0,1) < chanceRawAttack/7.0):
if rng.randf_range(0,1)<chanceToBind/2.0:
chooseAction("Beat","Bind",0,true)
elif rng.randf_range(0,1)<chanceToBeat/2.5:
chooseAction("Beat","Beat",0,true)
if rng.randf_range(0,1)<chanceToParryNew / 2.5:
chooseAction("Defense","Parry",0,true)
elif rng.randf_range(0,1) < chanceRawBigAttack * 4.0:
#print("AI is allowing a raw big attack!") #allowing; wont always be big, just allows the possibility
chooseAction("Attack","Medium",0,false)
else:
additionalRange = additionalRangeForSpam
chooseAction("Attack","Light",0,true)
func enemyActionDone(player : CharacterBody2D, actionName : String, actionType : String, actionCategory : String, range : Vector2,duration : float):
if player != chara:
if actionType == "Attack":
if actionCategory =="Light":
weightsTypes[actionType] = clampf(weightsTypes[actionType] + 1.0,0.0,40.0)
else:
weightsTypes[actionType] = clampf(weightsTypes[actionType] + 2.5,0.0,40.0)
else:
weightsTypes[actionType] = clampf(weightsTypes[actionType] + 1.0,0.0,40.0)
#maximumRange = range
beginReaction(actionCategory == "Heavy")
func beginReaction(reactingToHeavyAttack):
var reactionTimeNew = reactionTime
if reactingToHeavyAttack:
reactionTimeNew += 5 * .0167
$ReactionTimer.wait_time = reactionTimeNew
$ReactionTimer.start()
reacting = true
#REACTION
func _on_reaction_timer_timeout() -> void:
reacting = false
additionalRange = 0.0
if currentState.name == "Neutral":
if rng.randf_range(0,1)<chanceToParryReact:
chooseAction("Defense","Parry",0,true)
else:
punishBasedOnRange()
func chooseAction(actionType : String, actionCategory : String,searchIndex : int,mustBeCategory): #TODO searchIndex seems useless
if responding and searchIndex == 0:
return
responding = true
"""
var chosenAction
if actionType == "Attack":
if searchIndex>=attackList.size():
print_debug("Not a single move was viable for the AI to react with!")
return
chosenAction = attackList[searchIndex]
elif searchIndex>=moveList.size():
print_debug("AI ran out of possible moves to react with.")
return
"""
if searchIndex>=moveList.size():
#print("Not a single move was viable for the AI to react with!")
#print_debug(moveList.keys()[searchIndex-1])
responding = false
#clearQueue()
return
var chosenAction = moveList.keys()[searchIndex]
var actionRangeHypotenuse = sqrt(pow(moveList[chosenAction][4].x,2)+pow(moveList[chosenAction][4].y,2)) + additionalRange
newChanceToSkipAction = chanceToSkipAction
if abs(distance) > 15: #more likely to do an attack if closer
newChanceToSkipAction -= snapped(abs(1/pow(distance,.20)),.01)
else:
newChanceToSkipAction = .1
#currentState.moveList.has(chosenAction)
if currentState.canDoActionName(chosenAction) and actionType == moveList[chosenAction][2] and rng.randf_range(0,1) > newChanceToSkipAction and (rng.randf_range(0,1) > .94 or distance <= actionRangeHypotenuse): #if can do an action, is action in the available moves? is action viable for that state?
if mustBeCategory and moveList[chosenAction][3] != actionCategory:
#print_debug("The following move was not viable CATEGORY for the AI to react with: "+chosenAction)
chooseAction(actionType,actionCategory,searchIndex+1,mustBeCategory) #TODO wtf am i even writing anymore
else:
#print("Chose an action!")
doAction(chosenAction,moveList[chosenAction][1],moveList[chosenAction][2],moveList[chosenAction][3],moveList[chosenAction][4],moveList[chosenAction][5])
return
#print_debug("The following move was not viable for the AI to react with: "+chosenAction)
chooseAction(actionType,actionCategory,searchIndex+1,mustBeCategory)
func doAction(action,endState,type,category,range,duration):
#print("Doing action! "+action)
$ResponseTimer.start()
currentAction = action
currentState.constantAction = ""
currentState.doAction(action,endState,type,category,range,duration) #state.doAction(name)
clearQueue()
#responding = false
func queueAction(type,category,mustBeCategory):
queuing = true
queuedType = type
queuedCategory = category
queuedMustBeCategory = mustBeCategory
func clearQueue():
queuing = false
queuedType = null
queuedCategory = null
queuedMustBeCategory = null
func doConstantAction(action,inputDir):
if currentState.canDoConstantAction() and not responding: #TODO i dont like this
currentAction = action
currentState.doConstantAction(action,inputDir)
"""
func sendConstantAction(action): #intended to save memory, dont want to constantly communicate between scripts 24/7
if action != prevCurrentAction:
prevCurrentAction = action
if not doAction(action):
prevCurrentAction = ""
func doAction(action):
parent.get_node("StateMachine").doAction(action)
"""
func resetDictionaries(): #TODO useless
print("Reset the dictionaries")
func _on_freeze_ai_button_pressed() -> void:
set_physics_process(!is_physics_processing())
doConstantAction("Idle",Vector2(0,0))
#updateOriginalVariables()
#updateChanceVariables()
func setLabelVisibility():
var isVisible = label.visible
label.visible = !isVisible
label1.visible = !isVisible
labelWeights.visible = !isVisible
SliderReaction.visible = !isVisible
SliderSpam.visible=!isVisible
SliderAgro.visible=!isVisible
SliderParry.visible=!isVisible
SliderCareful.visible=!isVisible
chara.get_node("SliderInfo").visible=!isVisible
func _on_response_timer_timeout() -> void:
responding = false
func reactToLandedParry(perfect : bool):
if rng.randf_range(0,1) > chanceToPunish:
return
punishing = true
#if perfect:
# punishTime += (2 * .0167)
$PunishTimer.wait_time = punishTime
$PunishTimer.start()
#queueAction("Attack","Light",true)
func punishBasedOnRange():
if distance < 18.0: #TODO get rid of this once you add a doActionBasedOnRange() function
queueAction("Attack","Light",true)
elif distance < 35.0:
queueAction("Attack","Light",false)
else:
queueAction("Attack","Medium",true)
func _on_punish_timer_timeout() -> void:
punishBasedOnRange()
#await get_tree().create_timer(2 * .0167).timeout #just so that the AI has time for its punish before physics_process goes back to running the AI
punishing = false
func enemyHitboxGone(player, _framesLeft):
return #TODO I'll deal with this later since the AI already reacts
if player == chara:
return
print("HITBOX GONE")
if rng.randf_range(0,1) < chanceToPunish / 3.0:
punishing = true
$PunishTimer.wait_time = punishTime
$PunishTimer.start()
func canForwardParry():
if currentState != currentState.neutralState or responding or queuing or punishing:
return false
return rng.randf_range(0,1) < chanceToParryReact
func canBlock():
if blockAll:
return true
if currentState != currentState.neutralState or responding or queuing or punishing:
return false
return (currentAction=="WalkBackward") or rng.randf_range(0,1) < chanceToBlock
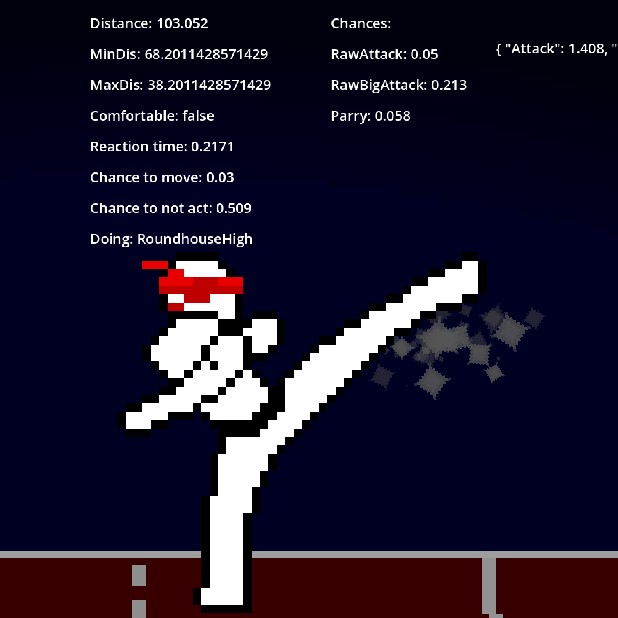
func setLabelText():
"""AILabelThinking.text = ("Reacting: "+str(reacting)+"
Responding: "+str(responding)+"
Queuing "+str(queuing)+"
Punishing "+str(punishing))
"""
if reacting:
label.text = (
"Distance: "+str(distance)+"
MinDis: "+str(minComfortDistance)+"
MaxDis: "+str(maxComfortDistance)+"
Comfortable: "+str(comfortable)+"
Reaction time: "+str(reactionTime)+"
Chance to move: "+str(chanceToChangeMovement)+"
Chance to not act: "+str(newChanceToSkipAction)+"
Doing: "+currentAction+"
Reacting!"
)
else:
label.text = (
"Distance: "+str(distance)+"
MinDis: "+str(minComfortDistance)+"
MaxDis: "+str(maxComfortDistance)+"
Comfortable: "+str(comfortable)+"
Reaction time: "+str(reactionTime)+"
Chance to move: "+str(chanceToChangeMovement)+"
Chance to not act: "+str(newChanceToSkipAction)+"
Doing: "+currentAction
)
label1.text = (
"Chances:
RawAttack: "+str(chanceRawAttack)+"
RawBigAttack: "+str(chanceRawBigAttack)+"
Parry: "+str(chanceToParryNew)
)
labelWeights.text = str(weightsTypes)
Colored visual effect that trails delayed
The coolest visual feature ever
How the rule of priority was programmed

{kind=link}